
Five years ago, I wrote the tutorial article "Lucene Full Text Search - A Very Basic Tutorial". It was a beginner's tutorial on integrating Lucene into a Java-based console application. Recently, I have picked up Lucene again for my small side project. Five years have passed, and a lot of changes happened with Lucene. When I did my work with this integration, I learned a few new things. I will be sharing these in this tutorial.
At first, I learned there have been multiple new releases on Lucene SDK. As a result, a few things in my old tutorial are no longer applied. The next problem I faced was the difference between StringField and TextField. I also learned a few new things:
This tutorial will explore all these points. Overall, the general approach to how Lucene can be integrated into your application is almost the same. What's changed is the actual code you should write. I will start from the beginning, explaining the basics of how to configure Lucene into your application, including the version and the jars you should include in your project, and what bootstrap steps are needed to have Lucene running in your application. And how to create indexes of documents, how to search them, and how to update the document when needed. This is going to be a fun tutorial.
This tutorial includes a very cool sample application. It is a Spring Boot based MVC application. It has the following functionalities:
What is cool about this application is that the user can create and modify an indexing repository and test the search on the documents. Then the indexing repository can be integrated into a different application. This assumes the other application uses the same document storage format and nearly the same search functionality as this sample application. I developed this idea while working on a Spring MVC static website. Rather than adding/editing the documents within that application, I separated out these document browsing, add/edit/delete functionalities into a new application -- the separation of responsibilities. You can use it for the same. Copy and paste your index, the document storage format type, and search functionality into your application. You will have the full-text search capability in your Java application.
For this sample application, I am using the latest Lucene SDK. I will begin with the jar dependencies needed for this sample application. Then I will discuss all the changes I made to get Lucene successfully integrated.
At the time of writing this tutorial, the latest Lucene SDK release has the version of 9.9.1. I included the following jars in my Maven POM file:
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>9.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>9.9.1</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-codecs</artifactId>
<version>9.9.1</version>
</dependency
The first jar dependency is needed to open a repository, and index the documents. The second jar is used for creating the queries to search for documents in the repository. The last one is used to privide the standard token analyzer for the indexing operations. In my previous tutorial, I only used the first jar dependency. With the new version, some of the query functionality and token analyzing functionality are no longer part of the Lucene-core jar dependency. I have to include the second and the third jar in order to get all my desired functionalities to compile correctly.
In the next section, I will be explaining all the lucene functionalities. I will also point out the place where the new jar dependencies are required for these functionalities.
Before I dive into the code, I like to explain what the document I like to index and retrieve. Such document has the following elements:
StringField. Another version is a long integer value, it has the value in the format like this: yyyyMMdd; Yes. I know the two values are diferent. This is a bug;These elements/fields should capture all the indexable/storage only aspects of your documents. If you need something more, you can always add more fields to capture them.
Most of the concepts employed by Lucene SDK to index or query documents remained the same since the time I wrote my first tutorial. An indexable document consists of multiple fields. Each field has a specific type. The most used type is the TextField. There are also the StringField (also a text-based indexable field), and the numeric fields like the LongField. Fields can be indexable field or non-indexable fields. The indexable fields are queryable; the latter are not. The field can be specified to store the original content or not. One thing I forgot is the difference between the StringField and TextField. The StringField treats the content as one token, while the TextField will break the words into tokens based on the token analyzer specified. Assuming they were the same, I used StringField for most of the fields, then my queries failed to find the results because the individual words failed to match anything in those fields. It took me a couple of hours to find the cause, only after I consulted with the latest documentation. I should have read my own tutorial before I started the work. That would save me the couple of hours I spent. If you want to know more about the many different types of fields, you can check out my previous tutorial. I have done a pretty good job in explaining them. The ways of how these fields behave are the same.
Here is my indexable document data type:
package org.hanbo.boot.rest.models;
import java.io.Serializable;
import java.text.SimpleDateFormat;
import java.util.Date;
import org.springframework.util.StringUtils;
import org.slf4j.*;
public class IndexableDocumentModel
implements Serializable
{
private static Logger _logger = org.slf4j.LoggerFactory.getLogger(IndexableDocumentModel.class);
private static final long serialVersionUID = 4473992068573410570L;
private String id;
private String title;
private String keywords;
private String type;
private String abstractText;
private String author;
private Date createdDate;
private String createdDateInputValue;
private Date updatedDate;
private String content;
private String contentUrl;
private boolean saveSuccess;
private String errorMessage;
public IndexableDocumentModel()
{
setErrorMessage("");
setCreatedDate(new Date());
}
public String getId()
{
return id;
}
public void setId(String id)
{
this.id = id;
}
public String getTitle()
{
return title;
}
public void setTitle(String title)
{
this.title = title;
}
public String getKeywords()
{
return keywords;
}
public void setKeywords(String keywords)
{
this.keywords = keywords;
}
public String getType()
{
return type;
}
public void setType(String type)
{
this.type = type;
}
public String getAbstractText()
{
return abstractText;
}
public void setAbstractText(String abstractText)
{
this.abstractText = abstractText;
}
public String getAuthor()
{
return author;
}
public void setAuthor(String author)
{
this.author = author;
}
public Date getCreatedDate()
{
return createdDate;
}
public void setCreatedDate(Date createdDate)
{
this.createdDate = createdDate;
SimpleDateFormat fmt = new SimpleDateFormat("yyyy-MM-dd");
String datevalText = fmt.format(createdDate);
this.setCreatedDateInputValue(datevalText);
}
public String getContent()
{
return content;
}
public void setContent(String content)
{
this.content = content;
}
public String getContentUrl()
{
return contentUrl;
}
public void setContentUrl(String contentUrl)
{
this.contentUrl = contentUrl;
}
public String getErrorMessage()
{
return errorMessage;
}
public void setErrorMessage(String errorMessage)
{
this.errorMessage = errorMessage;
}
public boolean isSaveSuccess()
{
return saveSuccess;
}
public void setSaveSuccess(boolean saveSuccess)
{
this.saveSuccess = saveSuccess;
}
public String getCreatedDateInputValue()
{
return createdDateInputValue;
}
public void setCreatedDateInputValue(String createdDateInputValue)
{
this.createdDateInputValue = createdDateInputValue;
}
public Date getUpdatedDate()
{
return updatedDate;
}
public void setUpdatedDate(Date updatedDate)
{
this.updatedDate = updatedDate;
}
public void convertDateTextToDateObject()
{
String dateText = getCreatedDateInputValue();
if (StringUtils.hasText(dateText))
{
SimpleDateFormat fmt = new SimpleDateFormat("yyyy-MM-dd");
try
{
Date dateVal = fmt.parse(dateText);
setCreatedDate(dateVal);
}
catch(Exception ex)
{
_logger.error("Exception occurred when attempt to convert string to Date object.", ex);
}
}
}
}
This data model object type is bound to the add/edit document page using ModelAttribute. One of the fields is used to specify the date when this document was created. I need two sets of property accessors for just this one date field. The last updated date field is automatically updated so there is just one set of accessors. I also included the properties of operation success and detailed error/success message to this data model because they are re-bound to the same page and can be used to display the status of the previous operation. You will see how this is used in the later sections.
The way a document is added to the Lucene index repository is as same as I have documented in my previous tutorial. Because of the changes over the past five years, I have to make a few changes. In the sample project, I have a service class implementation called DocumentIndexerServiceImpl. In it, you may find the following method:
@Override
public boolean indexDocument(Document docToIndex)
{
boolean retVal = false;
if (docToIndex == null)
{
_logger.error("Document to index is NULL. Unable to complete operation.");
return retVal;
}
IndexWriter writer = null;
try
{
Directory indexWriteToDir =
FSDirectory.open(Paths.get(indexDirectory));
IndexWriterConfig iwc = new IndexWriterConfig(new StandardAnalyzer());
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
iwc.setCodec(new SimpleTextCodec());
writer = new IndexWriter(indexWriteToDir, iwc);
writer.addDocument(docToIndex);
writer.flush();
writer.commit();
retVal = true;
}
catch(Exception ex)
{
_logger.error("Exception occurred when indexing document with id [%s].", ex);
retVal = false;
}
finally
{
if (writer != null)
{
try
{
writer.close();
}
catch(Exception ex)
{ }
}
}
return retVal;
}
In this method, the most essential part is in the try-catch block. I choose to write the document into a designated file directory. This is the easiest way of utilizing Lucene. You could also choose in-memory and some other storage medium for storing the index files. What is new is that I added the StandardAnalyzer object to the IndexWriterConfig object. For the same configuration object, I add a SimpleTextCodec object, so that the index writer can tokenize the text with the basic rules from U.S. English. I also set the open mode of this IndexWriterConfig object to "OpenMode.CREATE_OR_APPEND". This means basically if the dorectory does not have the index files, the writer uses this config object will create one; if there is one, then the new document will be appended to the index file.
The rest of the part creates the IndexWriter object and writes the document by calling its method AddDocument(). The Document object passed in as a method parameter will be the document to be added. Once completed, the writer object does a flush and commits the save. At the end of the method, the writer object will close.
Unlike the last tutorial, this sample application provides a page that allows the user to enter all the fields about the document, then click a button called "Save" and the application will save the document into the Lucene index. This is the screenshot of the page where the user can enter the information about the document:
As you can see from the screenshot, the page is a typical MVC-based web page. You enter the values for all the fields, and click the "Save" button at the bottom of the page. The document will be indexed in the Lucene index repository. This is the form I have defined in the file "addNew.html":
<form th:action="@{/addNewDocument}" th:object="${documentModel}" method="post" novalidate>
<div class="row" th:if='${documentModel.errorMessage != null && !documentModel.errorMessage.trim().equals("")}'>
<div class="col">
<div class="alert alert-danger" th:if="${documentModel.saveSuccess == false}" th:text="${documentModel.errorMessage}"></div>
<div class="alert alert-success" th:if="${documentModel.saveSuccess == true}" th:text="${documentModel.errorMessage}"></div>
</div>
</div>
<div class="row">
<div class="col mb-2">
<label for="titleField">Title</label>
<input th:field="${documentModel.title}" id="titleField" name="titleField" class="form-control" />
</div>
</div>
<div class="row">
<div class="col-4 mb-2">
<label for="contentTypeField">Content Type</label>
<input th:field="${documentModel.type}" id="contentTypeField" name="contentTypeField" class="form-control" />
</div>
</div>
<div class="row">
<div class="col-4 mb-2">
<label for="authorField">Author</label>
<input th:field="${documentModel.author}" id="authorField" name="authorField" class="form-control" />
</div>
</div>
<div class="row">
<div class="col-5 mb-2">
<label for="createdDateField">Created Date</label>
<input type="text" name="createdDateField" class="form-control"
th:field="${documentModel.createdDateInputValue}"
th:value="${documentModel.createdDate}?${#dates.format(documentModel.createdDate, 'yyyy-MM-dd')}:''"
placeholder="yyyy-MM-dd" id="createdDateField" />
</div>
</div>
<div class="row">
<div class="col mb-2">
<label for="keywordsField">Keywords</label>
<input th:field="${documentModel.keywords}" id="keywordsField" name="keywordsField" class="form-control" />
</div>
</div>
<div class="row">
<div class="col mb-2">
<label for="contentUrlField">Content URL</label>
<input th:field="${documentModel.contentUrl}" id="contentUrlField" name="contentUrlField" class="form-control" />
</div>
</div>
<div class="row">
<div class="col mb-2">
<label for="abstractTextField">Abstract</label>
<textarea th:field="${documentModel.abstractText}"
id="abstractTextField"
name="abstractTextField"
rows="4"
class="form-control fixed"></textarea>
</div>
</div>
<div class="row">
<div class="col mb-2">
<label for="contentField">Content to Index</label>
<textarea th:field="${documentModel.content}"
id="contentField"
name="contentField"
rows="7"
class="form-control fixed"></textarea>
</div>
</div>
<div class="row">
<div class="col">
<button class="btn btn-primary form-control" type="submit">Save</button>
</div>
<div class="col">
<button class="btn btn-default btn-outline-secondary form-control" type="reset">Clear</button>
</div>
</div>
</form>
There are a few things I want to explain with the above code snippet. First, I am using Spring MVC for the form handling and nothing else. The first thing you will notice is how the form is declared:
<form th:action="@{/addNewDocument}" th:object="${documentModel}" method="post" novalidate>
...
</form>
The action attribute (th:action) is the URL point to the action handler method that will process the document. What is interesting is the attribute called "object" (th:object). It specifies the binding data model to the form. In this case, the data model object that is passed from the controller is called "documentModel". The next block of HTML mark-up code displays the operation status:
<div class="row" th:if='${documentModel.errorMessage != null && !documentModel.errorMessage.trim().equals("")}'>
<div class="col">
<div class="alert alert-danger" th:if="${documentModel.saveSuccess == false}" th:text="${documentModel.errorMessage}"></div>
<div class="alert alert-success" th:if="${documentModel.saveSuccess == true}" th:text="${documentModel.errorMessage}"></div>
</div>
</div>
Remember I mentioned the two extra properties in the IndexableDocumentModel data type. They are used here. The code block will use the property saveSuccess to decide if a green status bar (when the value of it is true) or a red status bar will be displayed. In it, the message will indicate if the previous operation is successful or not. If there is no previous operation, nothing will be displayed.
For each field in this form, there is a binding of the field value to the property of the object type IndexableDocumentModel. This is an example:
<div class="row">
<div class="col mb-2">
<label for="abstractTextField">Abstract</label>
<textarea th:field="${documentModel.abstractText}"
id="abstractTextField"
name="abstractTextField"
rows="4"
class="form-control fixed"></textarea>
</div>
</div>
This is HTML element <textarea/>. There is the field attribute th:field that is mapped to object property documentModel.abstractText. When the page is posted to the server, the fields of this form will be transformed into the data object of type IndexableDocumentModel and passed to the method that will handle the request from this form.
The Java code that first initiate the displaying of this page is as the following:
@RequestMapping(value="/addNewHtmlDoc", method=RequestMethod.GET)
public String addNewHtmlDoc(Model model)
{
HtmlDocumentInputModel modelToAdd = new HtmlDocumentInputModel();
model.addAttribute("documentModel", modelToAdd);
return "addNewHtmlDoc";
}
When the user fills out the form and click the button "Save", the request will be handled by the following method:
@RequestMapping(value="/addNewDocument", method=RequestMethod.POST)
public String addNewDocument(Model model,
@ModelAttribute("documentModel")
IndexableDocumentModel docToAdd)
{
if (docToAdd != null)
{
docToAdd.setUpdatedDate(new Date());
addNewDocument(docToAdd, model);
}
else
{
IndexableDocumentModel modelToAdd = new IndexableDocumentModel();
modelToAdd.setSaveSuccess(false);
modelToAdd.setErrorMessage("The input document content data model is NULL.");
model.addAttribute("documentModel", modelToAdd);
}
return "addNew";
}
This method doesn't do much. It delegates most of the work to a private method called addNewDocument(). The reason I use this private method is that the sample application has two places where it handles a document being added into the Lucene index repository, here and the method where the application tries to index an HTML document. Both shares the same functionality. Here is the private method addNewDocument():
private String addNewDocument(IndexableDocumentModel docToAdd, Model model)
{
boolean docValid = _docIndexSvc.validateDocumentModel(docToAdd);
if (!docValid)
{
model.addAttribute("documentModel", docToAdd);
return "addNew";
}
docToAdd.convertDateTextToDateObject();
Document indexableDoc = _docIndexSvc.createIndexableDocument(docToAdd);
if (indexableDoc != null)
{
boolean opSuccess = _docIndexSvc.indexDocument(indexableDoc);
if (opSuccess)
{
IndexableDocumentModel modelToAdd = new IndexableDocumentModel();
modelToAdd.setSaveSuccess(opSuccess);
modelToAdd.setErrorMessage("Document content has been indexed successfully.");
model.addAttribute("documentModel", modelToAdd);
return "addNew";
}
else
{
docToAdd.setSaveSuccess(opSuccess);
docToAdd.setErrorMessage("Unable to index document content. Please see the server log for more details.");
model.addAttribute("documentModel", docToAdd);
return "addNew";
}
}
else
{
docToAdd.setSaveSuccess(false);
docToAdd.setErrorMessage("Unable to create indexable document from the input document model. Please see the server log for more details.");
model.addAttribute("documentModel", docToAdd);
return "addNew";
}
}
This method is not hard to understand. First it validates the IndexableDocumentModel data object. if there is any issue with the data object (like certain properties not filled out), it will set the status to failed and status message to be displayed. The same data object will be returned to the page "addNew.html". Then the method will convert the IndexableDocumentModel data object to a Lucene Document object. This is the one that Lucene will index. Finally, the Document object will be passed to the method indexDocument() of object type DocumentIndexerService. This indexDocument() is the one we have seen at the very top of this sub-section. And this is the method that converts the IndexableDocumentModel data object to the Lucene Document object:
@Override
public Document createIndexableDocument(IndexableDocumentModel inDocModel)
{
Document retVal = null;
if (inDocModel != null)
{
retVal = new Document();
String docId = IdUtils.generateDocumentId();
IndexableField idField = new StringField("DOCID", docId, Field.Store.YES);
retVal.add(idField);
IndexableField titleField = new TextField("TITLE", inDocModel.getTitle(), Field.Store.YES);
retVal.add(titleField);
IndexableField docTypeField = new StringField("DOCTYPE", inDocModel.getType(), Field.Store.YES);
retVal.add(docTypeField);
IndexableField authorField = new TextField("AUTHOR", inDocModel.getAuthor(), Field.Store.YES);
retVal.add(authorField);
IndexableField keywordsField = new TextField("KEYWORDS", inDocModel.getKeywords(), Field.Store.YES);
retVal.add(keywordsField);
IndexableField abstractTextField = new TextField("ABSTRACT", inDocModel.getAbstractText(), Field.Store.YES);
retVal.add(abstractTextField);
IndexableField contentUrlField = new StoredField("PATH", inDocModel.getContentUrl());
retVal.add(contentUrlField);
IndexableField contentTextField = new TextField("CONTENT", inDocModel.getContent(), Field.Store.YES);
retVal.add(contentTextField);
IndexableField createdDateField = new LongField("CREATEDDATE", DateUtils.convertDateToLong(inDocModel.getCreatedDate()), Field.Store.YES);
retVal.add(createdDateField);
IndexableField createdDateTextField = new StringField("CREATEDDATETEXT", DateUtils.convertDateToText(inDocModel.getCreatedDate(), false), Field.Store.YES);
retVal.add(createdDateTextField);
IndexableField updatedDateField = new LongField("UPDATEDDATE", DateUtils.convertDateToLong(inDocModel.getUpdatedDate()), Field.Store.YES);
retVal.add(updatedDateField);
IndexableField updatedDateTextField = new StringField("UPDATEDDATETEXT", DateUtils.convertDateToText(inDocModel.getUpdatedDate(), true), Field.Store.YES);
retVal.add(updatedDateTextField);
}
return retVal;
}
That is all there is about adding a document into the Lucene dindex repository. You can find all these in the classes DocumentIndexingController and DocumentIndexerServiceImpl. Next, I will discuss something I have done in my previous tutorial -- how to list all the documents in the Lucene index repository and how to edit/delete the documents.
Lucene index repository is like a database. Unfortunately, there wasn't a free tool that allows me to look into the repository, and edit or delete the documents at will. I personallly didn't know or search a tool like this. I just wrote the functionalities in this sample application. Let's take a look at the first functionality -- how to list all the documents in the repository.
In the class DocumentIndexingController, there is the action method called listAll(). This method will load all the documents. I didn't put in anything for pagination. All results are displayed in the same page. This is what the listAll() looks like:
@RequestMapping(value="/listAll", method=RequestMethod.GET)
public String listAll(Model model)
{
List allDocs = _docIndexSvc.allDocuments();
if (allDocs != null && !allDocs.isEmpty())
{
model.addAttribute("allDocuments", allDocs);
for (IndexedDocumentListItem itm : allDocs)
{
debugOutputIndexedDocument(itm);
}
}
else
{
model.addAttribute("allDocuments", new ArrayList<IndexedDocumentListItem>());
}
return "listAll";
}
It doesn't really do much. The actual work is done by the method allDocuments() in the service object type DocumentIndexerServiceImpl. And this method looks like this:
@Override
public List<IndexedDocumentListItem> allDocuments()
{
List<IndexedDocumentListItem> retVal = new ArrayList<IndexedDocumentListItem>();
try
{
Directory dirOfIndexes =
FSDirectory.open(Paths.get(indexDirectory));
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(dirOfIndexes));
QueryParser queryParser = new QueryParser("title", new StandardAnalyzer());
Query query = queryParser.parse("*:*");
TopDocs allFound = searcher.search(query, 32767);
if (allFound.scoreDocs != null)
{
StoredFields storedFields = searcher.storedFields();
for (ScoreDoc doc : allFound.scoreDocs)
{
int docidx = doc.doc;
Document docRetrieved = storedFields.document(docidx);
if (docRetrieved != null)
{
IndexedDocumentListItem docToAdd = createIndexedDocumentListItem(docidx, docRetrieved);
retVal.add(docToAdd);
}
}
}
}
catch (Exception ex)
{
_logger.error("Exception occurred when loading all indexed documents", ex);
retVal = new ArrayList<IndexedDocumentListItem>();
}
return retVal;
}
I did wonder how I can load all the documents in the repository. Turned out, the simplest way is to search any text for all the fields, and it will return all the documents. You can do this with these few lines:
...
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(dirOfIndexes));
QueryParser queryParser = new QueryParser("title", new StandardAnalyzer());
Query query = queryParser.parse("*:*");
TopDocs allFound = searcher.search(query, 32767);
...
In the above code, I create a IndexSearcher object. Then I create a QueryParser object. Note that QueryParser object is of type org.apache.lucene.queryparser.classic.QueryParser. The QueryParser object can prepare a Query object for you so that it can be passed to searcher.search(). The second parameter is the maximum number of results to be returned. I hard code it to 32,767 results. All of the results are stored in a TopDocs object. The rest of the method is iterating through the results and converted into IndexedDocumentListItem objects, and be displayed on the page "listAll.html":
...
if (allFound.scoreDocs != null)
{
StoredFields storedFields = searcher.storedFields();
for (ScoreDoc doc : allFound.scoreDocs)
{
int docidx = doc.doc;
Document docRetrieved = storedFields.document(docidx);
if (docRetrieved != null)
{
IndexedDocumentListItem docToAdd = createIndexedDocumentListItem(docidx, docRetrieved);
retVal.add(docToAdd);
}
}
}
...
See? This is not too hard. Well, the next topic of discussion is how to locate a document and delete it. And it is not too hard either. Every document has a unique document ID. All I have to do is pass the document ID and the name of the field name to the right Lucene API and it will remove the document for you. In this controller class DocumentIndexingController, you will find this method handles the document deletion request:
@RequestMapping(value="/deleteIndexedDocument", method=RequestMethod.POST, consumes = {"application/x-www-form-urlencoded"})
public String deleteIndexedDocument(
@RequestParam
Map<String, Object> paramMap,
Model model)
{
String documentId = (String)paramMap.get("documentId");
if (StringUtils.hasText(documentId))
{
boolean opSuccess = _docIndexSvc.deleteIndexedDocument(documentId);
if (opSuccess)
{
model.addAttribute("changeOpSuccess", true);
model.addAttribute("changeOpOutcome", "Document with index id has been deleted successfully.");
}
else
{
model.addAttribute("changeOpSuccess", false);
model.addAttribute("changeOpOutcome", "Unable to delete document with index id. Please check the server log for more details.");
}
}
List<IndexedDocumentListItem> allDocs = _docIndexSvc.allDocuments();
if (allDocs != null && !allDocs.isEmpty())
{
model.addAttribute("allDocuments", allDocs);
}
else
{
model.addAttribute("allDocuments", new ArrayList<IndexedDocumentListItem>());
}
return "listAll";
}
What this method does is first delegate the deletion operation to the service object's method deleteIndexedDocument. Then it loads all the documents and displays them on the page "listAll.html".
The method that does the deletion, which is in the class DocumentIndexerServiceImpl, looks like this:
@Override
public boolean deleteIndexedDocument(String uniqueId)
{
try
{
Directory dirOfIndexes =
FSDirectory.open(Paths.get(indexDirectory));
IndexWriter writer = new IndexWriter(dirOfIndexes, new IndexWriterConfig(new StandardAnalyzer()));
writer.deleteDocuments(new Term("DOCID", uniqueId));
writer.flush();
writer.commit();
writer.close();
return true;
}
catch (Exception ex)
{
_logger.error(String.format("Exception occurred when attempting to delete document with id [%s]. Exception message: [%s]", uniqueId, ex.getMessage()), ex);
return false;
}
}
The IndexWriter class has this method deleteDocuments(). The way this method works is first to use some query to find all the matching documents, then delete them from the Lucene index repository. I must pass in a Term object. A Term object is a unit of query. It has a field and a string value that you want to match to this field. To delete just one document, I need to use the document ID to identify the document uniquely. This is why I pass in a Term object with the field name set to "DOCID", and the document ID (a UUID value without the dash) to this method. And it works exactly as it is designed to do. This is the new concept I learned, if I need to get to a document based on its unique document ID, I can use a Term based query and pass it to the Lucene API I needed to call.
Updating an existing document is pretty simple as well. When I did my research, the online resources was not clear on how it is done. After some digging in the Lucene documentation, I realized the update operation is a two-step operation. First, it locates the document to be updated, and deletes it. Then, it inserts the updated document into the index. So, the updating operation is essentially a delete-then-replace operation. In this controller class DocumentIndexingController, you will find this method handles the document update request:
@RequestMapping(value="/updateDocument", method=RequestMethod.POST)
public String updateDocument(Model model,
@ModelAttribute("documentModel")
IndexableDocumentModel docToUpdate)
{
if (docToUpdate != null)
{
String docId = docToUpdate.getId();
System.out.println("Created date: " + docToUpdate.getCreatedDateInputValue());
if (StringUtils.hasText(docId))
{
// Update the document.
String retVal = updateDocument(docToUpdate, model);
return retVal;
}
else
{
// treat this as a new document and add it to index.
String retVal = addNewDocument(docToUpdate, model);
return retVal;
}
}
else
{
_logger.error("Unable to update existing document. Document model data object is NULL or empty.");
IndexableDocumentModel modelToAdd = new IndexableDocumentModel();
modelToAdd.setSaveSuccess(false);
modelToAdd.setErrorMessage("Unable to update existing document. Document model data object is NULL or empty.");
model.addAttribute("documentModel", modelToAdd);
return "addNew";
}
}
The above method takes the input document data model and first gets the document ID. If the document ID does not exist, then the file is treated as a new document to be added. If the doucment ID exists, then a update of the existing document will be performed. The operation is delegated to the method updateDocument() in the same class. This method updateDocument() looks like this:
private String updateDocument(IndexableDocumentModel docToUpdate, Model model)
{
boolean docValid = _docIndexSvc.validateDocumentModel(docToUpdate);
if (!docValid)
{
model.addAttribute("documentModel", docToUpdate);
return "editExisting";
}
docToUpdate.setUpdatedDate(new Date());
boolean opSuccess = _docIndexSvc.updateIndexableDocument(docToUpdate);
docToUpdate.setSaveSuccess(opSuccess);
if (opSuccess)
{
docToUpdate.setErrorMessage("This document has been updated successfully.");
model.addAttribute("documentModel", docToUpdate);
return "editExisting";
}
else
{
docToUpdate.setErrorMessage("Unable to update this document. Please see backend server log for more details.");
model.addAttribute("documentModel", docToUpdate);
return "editExisting";
}
}
In this method, the document update operation is again delegated to another method, which is located in the service object of type DocumentIndexerServiceImpl. The new method is called updateIndexableDocument(). It looks like this:
@Override
public boolean updateIndexableDocument(IndexableDocumentModel inDocModel)
{
boolean retVal = false;
if (inDocModel == null)
{
_logger.error("Document to index is NULL. Unable to complete operation.");
return retVal;
}
inDocModel.convertDateTextToDateObject();
String docId = inDocModel.getId();
if (StringUtils.hasText(docId))
{
Document updatedDocument = createIndexableDocument(inDocModel);
IndexableField idField = new StringField("DOCID", docId, Field.Store.YES);
updatedDocument.add(idField);
IndexWriter writer = null;
try
{
Directory indexWriteToDir =
FSDirectory.open(Paths.get(indexDirectory));
IndexWriterConfig iwc = new IndexWriterConfig(new StandardAnalyzer());
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
iwc.setCodec(new SimpleTextCodec());
writer = new IndexWriter(indexWriteToDir, iwc);
writer.updateDocument(new Term("DOCID", docId), updatedDocument);
writer.flush();
writer.commit();
_logger.info(String.format("Successfully update indexed document with id [%s].", docId));
retVal = true;
}
catch(Exception ex)
{
_logger.error("Exception occurred when updating indexed document of id [%s].", ex);
retVal = false;
}
finally
{
if (writer != null)
{
try
{
writer.close();
}
catch(Exception ex)
{ }
}
}
return retVal;
}
else
{
_logger.error("Unable to update document. The document ID is null or empty. Please add this as a new document to the index.");
return false;
}
}
This method might be bit confusing. Let me explain starting from the beginning. Once the method gets the input document for updating, it will first create a new Lucene Document from the input. Then I need to assign the same document ID to this new document object. Here are the code:
...
Document updatedDocument = createIndexableDocument(inDocModel);
IndexableField idField = new StringField("DOCID", docId, Field.Store.YES);
updatedDocument.add(idField);
...
This is the code that takes the new document and replace the old one in the Lucene index repository:
...
Directory indexWriteToDir =
FSDirectory.open(Paths.get(indexDirectory));
IndexWriterConfig iwc = new IndexWriterConfig(new StandardAnalyzer());
iwc.setOpenMode(OpenMode.CREATE_OR_APPEND);
iwc.setCodec(new SimpleTextCodec());
writer = new IndexWriter(indexWriteToDir, iwc);
writer.updateDocument(new Term("DOCID", docId), updatedDocument);
writer.flush();
writer.commit();
...
The lines that does delete and insert of document is this:
...
writer.updateDocument(new Term("DOCID", docId), updatedDocument);
writer.flush();
writer.commit();
...
As shown, the update is also done by passing in a Term object to locate the document to be replaced. And the new document object created in the method will replace the existing one.
Now, we have seen how to add a new document, how to update the existing one, and how to locate and delete an existing document. The last functionality I want to show is how to query the documents.
In my previous tutorial, I explained how to do query using Lucene search functionality. I didn't say is that the functionlaity I implemented is primitive. I can search with one word and get results. When I put in multiple words, the search will break. I thought about it for the past five years how I can improve the work so that the input string can have multiple words instead of single word.
The solution I come up is a simple one, I can break the string into a list of words. And I generate the query for every word for all the fields. Then I combine the queries using the logic operator "OR".
In the controller class IndexController, you can find this method that handles the full text search:
@RequestMapping(value="/searchFor", method=RequestMethod.POST)
public String searchFor(Model model,
@ModelAttribute("searchInput")
SearchForInputModel searchInput)
{
if (searchInput != null)
{
String searchText = searchInput.getSearchText();
if (StringUtils.hasText(searchText))
{
List<IndexedDocumentListItem> allMatchedDocs
= _docIndexSvc.searchFor(searchText);
if (allMatchedDocs != null && !allMatchedDocs.isEmpty())
{
model.addAttribute("allDocuments", allMatchedDocs);
for (IndexedDocumentListItem itm : allMatchedDocs)
{
debugOutputIndexedDocument(itm);
}
}
else
{
model.addAttribute("changeOpSuccess", false);
model.addAttribute("changeOpOutcome", String.format("No document found for the query \"%s\".", searchText));
model.addAttribute("allDocuments", new ArrayList<IndexedDocumentListItem>());
}
}
else
{
model.addAttribute("changeOpSuccess", false);
model.addAttribute("changeOpOutcome", "Please enter some text to search the indexed documents.");
model.addAttribute("allDocuments", new ArrayList<IndexedDocumentListItem>());
}
}
return "listAll";
}
As before, this full-text search functionality is delegated to the service object. The method is called searchFor(). It is located in the class DocumentIndexerServiceImpl. This method looks like the following:
@Override
public List<IndexedDocumentListItem> searchFor(String searchText)
{
List<IndexedDocumentListItem> retVal = new ArrayList<IndexedDocumentListItem>();
if (StringUtils.hasText(searchText))
{
List<String> allSearchKeywords = splitSearchText(searchText);
if (allSearchKeywords != null && !allSearchKeywords.isEmpty())
{
QueryBuilder bldr = new QueryBuilder(new StandardAnalyzer());
BooleanQuery.Builder chainQryBldr = new BooleanQuery.Builder();
for (String txtToSearch : allSearchKeywords)
{
Query q1 = bldr.createPhraseQuery("TITLE", txtToSearch);
Query q2 = bldr.createPhraseQuery("KEYWORDS", txtToSearch);
Query q3 = bldr.createPhraseQuery("CONTENT", txtToSearch);
Query q4 = bldr.createPhraseQuery("DOCTYPE", txtToSearch);
Query q5 = bldr.createPhraseQuery("AUTHOR", txtToSearch);
Query q6 = bldr.createPhraseQuery("ABSTRACT", txtToSearch);
chainQryBldr.add(q1, Occur.SHOULD);
chainQryBldr.add(q2, Occur.SHOULD);
chainQryBldr.add(q3, Occur.SHOULD);
chainQryBldr.add(q4, Occur.SHOULD);
chainQryBldr.add(q5, Occur.SHOULD);
chainQryBldr.add(q6, Occur.SHOULD);
}
BooleanQuery finalQry = chainQryBldr.build();
System.out.println("Final Query: " + finalQry.toString());
try
{
Directory dirOfIndexes =
FSDirectory.open(Paths.get(indexDirectory));
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(dirOfIndexes));
TopDocs allFound = searcher.search(finalQry, 100);
if (allFound.scoreDocs != null)
{
System.out.println("score doc not empty");
StoredFields storedFields = searcher.storedFields();
System.out.println(allFound.scoreDocs.length);
for (ScoreDoc doc : allFound.scoreDocs)
{
System.out.println("For each score doc");
System.out.println("Score: " + doc.score);
int docidx = doc.doc;
Document docRetrieved = storedFields.document(docidx);
if (docRetrieved != null)
{
IndexedDocumentListItem docToAdd = createIndexedDocumentListItem(docidx, docRetrieved);
retVal.add(docToAdd);
}
}
}
}
catch (Exception ex)
{
_logger.error("Exception occurred when attempt to search for document.", ex);
retVal = new ArrayList<IndexedDocumentListItem>();
}
}
}
return retVal;
}
This method can be broken into two parts:
As I have discussed before, I need to break the input value (a sentence of English words) into a list of words, then each word is searched in every searchable field. This is how it is done:
List<String> allSearchKeywords = splitSearchText(searchText);
if (allSearchKeywords != null && !allSearchKeywords.isEmpty())
{
QueryBuilder bldr = new QueryBuilder(new StandardAnalyzer());
BooleanQuery.Builder chainQryBldr = new BooleanQuery.Builder();
for (String txtToSearch : allSearchKeywords)
{
Query q1 = bldr.createPhraseQuery("TITLE", txtToSearch);
Query q2 = bldr.createPhraseQuery("KEYWORDS", txtToSearch);
Query q3 = bldr.createPhraseQuery("CONTENT", txtToSearch);
Query q4 = bldr.createPhraseQuery("DOCTYPE", txtToSearch);
Query q5 = bldr.createPhraseQuery("AUTHOR", txtToSearch);
Query q6 = bldr.createPhraseQuery("ABSTRACT", txtToSearch);
chainQryBldr.add(q1, Occur.SHOULD);
chainQryBldr.add(q2, Occur.SHOULD);
chainQryBldr.add(q3, Occur.SHOULD);
chainQryBldr.add(q4, Occur.SHOULD);
chainQryBldr.add(q5, Occur.SHOULD);
chainQryBldr.add(q6, Occur.SHOULD);
}
BooleanQuery finalQry = chainQryBldr.build();
System.out.println("Final Query: " + finalQry.toString());
...
}
The last line in the above code snippet displays what the final query looks like. If I have a sentence like this "Brown Fox Jumps Over Lazy Dog", the final Lucene query will be like this:
TITLE:brown KEYWORDS:brown CONTENT:brown DOCTYPE:brown AUTHOR:brown ABSTRACT:brown TITLE:fox KEYWORDS:fox CONTENT:fox DOCTYPE:fox AUTHOR:fox ABSTRACT:fox TITLE:jumps KEYWORDS:jumps CONTENT:jumps DOCTYPE:jumps AUTHOR:jumps ABSTRACT:jumps TITLE:over KEYWORDS:over CONTENT:over DOCTYPE:over AUTHOR:over ABSTRACT:over TITLE:lazy KEYWORDS:lazy CONTENT:lazy DOCTYPE:lazy AUTHOR:lazy ABSTRACT:lazy TITLE:dog KEYWORDS:dog CONTENT:dog DOCTYPE:dog AUTHOR:dog ABSTRACT:dog
To search for the documents, and converting the result, this is how it is done:
try
{
Directory dirOfIndexes =
FSDirectory.open(Paths.get(indexDirectory));
IndexSearcher searcher = new IndexSearcher(DirectoryReader.open(dirOfIndexes));
TopDocs allFound = searcher.search(finalQry, 100);
if (allFound.scoreDocs != null)
{
System.out.println("score doc not empty");
StoredFields storedFields = searcher.storedFields();
System.out.println(allFound.scoreDocs.length);
for (ScoreDoc doc : allFound.scoreDocs)
{
System.out.println("For each score doc");
System.out.println("Score: " + doc.score);
int docidx = doc.doc;
Document docRetrieved = storedFields.document(docidx);
if (docRetrieved != null)
{
IndexedDocumentListItem docToAdd = createIndexedDocumentListItem(docidx, docRetrieved);
retVal.add(docToAdd);
}
}
}
}
catch (Exception ex)
{
_logger.error("Exception occurred when attempt to search for document.", ex);
retVal = new ArrayList<IndexedDocumentListItem>();
}
Once the results are converted into a list of displayable documents, they will be passed to the Thymeleaf page template "listAll.html". Please check it out if you want to know how they are displayed.
In the next sub-section, I will explain how to extract the data from an HTML page and use them for document indexing. This would be the last part of this tutorial.
Imagine that I have a website that has 50+ or maybe more pages. All of them are loaded with great content. For this particular project, no SQL database would be used and all pages are static pages. I need to index all these pages into the index repository. The most convenient way is to fetch the page, parse it for the data for the fields, and then index it. All of these can be done with automation. In this case, I can offer the next best thing, I have the page source code. I hand it to this sample application. The application will parse the data and do the indexing.
Parsing the page source is not hard. I have already explained how the indexing would work in the above sub-sections. The hard part is to have the correct format so that the HTML page can be easily parsed to get the fields' data. As long as I have control of the website and web pages, setting the right format for the pages is not hard at all. Here are the rules I set for a parsable web page:
<b/>, <u/>, <i/>, <span/>, <th/>, and <td/>.
Now the rules havve been set, all I need is something that I can use to parse these information. And that something is JSoup. This Java library behaves almost the same as JavaScript does. For example, there is the getElementById() in JavaScript. There is also one in this JSoup library. Similarly, several other Dom parsing functions from JavaScript can be found in JSoup. And their functionalities are structurely identical. So learning using JSoup to parse HTML page is pretty easy if you know JavaScript well enough.
To get all the meta tags of the HTML page, I use the JSoup API method calle getElementsByTags(). Once I get all the meta tags, I can go over all of them and parse data for the fields. You can find how this is done in the file "HtmlParserServiceImpl.java". The method is parseMetaFieldsForIndexing():
private void parseMetaFieldsForIndexing(Document htmlDoc, IndexableDocumentModel docToIndex)
{
Elements metaElements = htmlDoc.getElementsByTag("meta");
for (Element elem : metaElements)
{
String metaKey = elem.attr("name");
if (!StringUtils.hasText(metaKey))
{
metaKey = elem.attr("property");
}
if (StringUtils.hasText(metaKey))
{
metaKey = metaKey.trim();
}
String metaVal = elem.attr("content");
if (StringUtils.hasText(metaVal))
{
metaVal = metaVal.trim();
}
if (StringUtils.hasText(metaKey) && StringUtils.hasText(metaVal))
{
if (metaKey.equalsIgnoreCase("author"))
{
docToIndex.setAuthor(metaVal);
}
else if (metaKey.equalsIgnoreCase("description"))
{
docToIndex.setAbstractText(metaVal);
}
else if (metaKey.equalsIgnoreCase("keywords"))
{
docToIndex.setKeywords(metaVal);
}
else if (metaKey.equalsIgnoreCase("page_type"))
{
docToIndex.setType(metaVal);
}
else if (metaKey.equalsIgnoreCase("created_ts"))
{
if (StringUtils.hasText(metaVal))
{
try
{
Date createdTs = org.hanbo.boot.rest.services.utils.DateUtils.convertTextToDate(metaVal, false);
docToIndex.setCreatedDate(createdTs);
}
catch(Exception ex)
{
_logger.error(String.format("Unable to parse date value for created_ts. Date value [%s]. Setting the current dare as created_ts.", metaVal), ex);
docToIndex.setCreatedDate(new Date());
}
}
}
}
}
}
The above code snippet does not have parse the title of the HTML page. Title is often in the tag <title/>, which is located in the <head/> section of the HTML page. Here is how I extract it:
private void parseHtmlForTitle(Document htmlDoc, IndexableDocumentModel docToIndex)
{
Elements titleElems= htmlDoc.getElementsByTag("title");
if (titleElems.size() >= 1)
{
Element titleElem = titleElems.first();
if (titleElem != null)
{
String titleVal = titleElem.text();
if (StringUtils.hasText(titleVal))
{
titleVal = titleVal.trim();
if (StringUtils.hasText(titleVal))
{
System.out.println("Title: " + titleVal);
docToIndex.setTitle(titleVal);
}
}
}
}
}
Parsing for those meta fields is easy. The hard part is getting the entire content out of the body of the HTML page. And the code looks like this:
private void parseHtmlForBodyContent(Document htmlDoc, IndexableDocumentModel docToIndex)
{
Elements allElems = htmlDoc.body().select("*");
StringBuilder sb = new StringBuilder();
for (Element elem : allElems)
{
String tagName = elem.tagName();
tagName = tagName.trim();
if (StringUtils.hasText(tagName))
{
if (tagName.equalsIgnoreCase("h1")
|| tagName.equalsIgnoreCase("h2")
|| tagName.equalsIgnoreCase("h3")
|| tagName.equalsIgnoreCase("h4")
|| tagName.equalsIgnoreCase("h5")
|| tagName.equalsIgnoreCase("h6")
|| tagName.equalsIgnoreCase("a")
|| tagName.equalsIgnoreCase("p")
|| tagName.equalsIgnoreCase("span")
|| tagName.equalsIgnoreCase("i")
|| tagName.equalsIgnoreCase("b")
|| tagName.equalsIgnoreCase("u")
|| tagName.equalsIgnoreCase("li")
|| tagName.equalsIgnoreCase("th")
|| tagName.equalsIgnoreCase("td"))
{
String innerText = elem.text();
if (StringUtils.hasText(innerText))
{
sb.append(innerText);
sb.append(" ");
}
}
}
}
String contentToIndex = sb.toString();
if (StringUtils.hasText(contentToIndex))
{
System.out.println("Content: [[[" + contentToIndex + "]]]");
docToIndex.setContent(contentToIndex);
}
}
As you can see, the method is not complex. It find all the child nodes under the node <body/>. Then we just process these nodes in a for-loop. If it finds the tag it is expecting, it will extract the inner text. Then the text will be appended to the StringBuilder object. After appending, I have to add a space to the string so that we don't accidentally combine two words into one.
In the same class, you will see this method that parses the whole HTML page. It uses all the methods I have described above:
@Override
public IndexableDocumentModel parseHtmlForIndexableDocument(String contentUrl, String htmlDocStr)
{
IndexableDocumentModel retVal = null;
if (StringUtils.hasText(htmlDocStr))
{
retVal = new IndexableDocumentModel();
Document htmlDoc = Jsoup.parse(htmlDocStr, "", Parser.xmlParser());
parseMetaFieldsForIndexing(htmlDoc, retVal);
parseHtmlForTitle(htmlDoc, retVal);
parseHtmlForBodyContent(htmlDoc, retVal);
String docId = IdUtils.generateDocumentId();
retVal.setId(docId);
retVal.setContentUrl(contentUrl);
retVal.setUpdatedDate(new Date());
}
return retVal;
}
This is the place where the above method is being called to parse the HTML page and indexing it. You can find this in the class DocumentIndexingController:
@RequestMapping(value="/addNewHtmlDocument", method=RequestMethod.POST)
public String addNewHtmlDocument(Model model,
@ModelAttribute("documentModel")
HtmlDocumentInputModel docToAdd)
{
if (docToAdd != null)
{
String htmlDocToIndex = docToAdd.getHtmlDocContent();
if (StringUtils.hasText(htmlDocToIndex))
{
boolean opSuccess = _docIndexSvc.addHtmlDocumentToIndexRepository(docToAdd.getHtmlContentUrl(), htmlDocToIndex);
if (opSuccess)
{
HtmlDocumentInputModel modelToAdd = new HtmlDocumentInputModel();
modelToAdd.setSaveSuccess(true);
modelToAdd.setErrorMessage("The HTML document has been saved successfully.");
model.addAttribute("documentModel", modelToAdd);
}
else
{
docToAdd.setSaveSuccess(false);
docToAdd.setErrorMessage("Unable to save the HTML document you entered to document repository. Please see the backend server log for more details.");
model.addAttribute("documentModel", docToAdd);
}
}
else
{
docToAdd.setSaveSuccess(false);
docToAdd.setErrorMessage("Please enter your HTML document to be indexed.");
model.addAttribute("documentModel", docToAdd);
}
}
else
{
HtmlDocumentInputModel modelToAdd = new HtmlDocumentInputModel();
modelToAdd.setSaveSuccess(false);
modelToAdd.setErrorMessage("Invalid input data model. Please enter the HTML document before clicking the button \"Save\".");
model.addAttribute("documentModel", modelToAdd);
}
return "addNewHtmlDoc";
}
This is all on how to parse the HTML page for document indexing. I like to point out for a few things:
Anyways, that is it. All the technical details explained. In the next section, I will discuss how to use this web application so that you can create you own index repository.
After downloadinng the source code, and before building the sample application, you must first change the directory where the Lucene index repository is kept. This can be found in the sample application's configuration file called "application.properties". You can find this file in the resources directory under the src folder.
This file looks like this:
spring.servlet.multipart.max-file-size=400MB spring.servlet.multipart.max-request-size=2GB indexer.dataFolder=/home/hanbosun/Projects/DevJunk/hangofishing/index_data
The first two lines are not used by this application. They are nice to have. The third line is the one that you want to modify. The value is specific to my PC. You need to change it specific to your file system.
After changing the path, and saved this configuration file, it is time to build it. You run the following command at the base directory:
mvn clean install
After the build is successful, you can run the following command:
java -jar target/hanbo-spring-se-indexer-1.0.1.jar
When the application is successfully running, you copy and paste the following URL into the browser, then hit enter:
http://localhost:8080/
If you did everything correctly, the index page of this sample application will display when you navigate into the above URL. It looks like this:
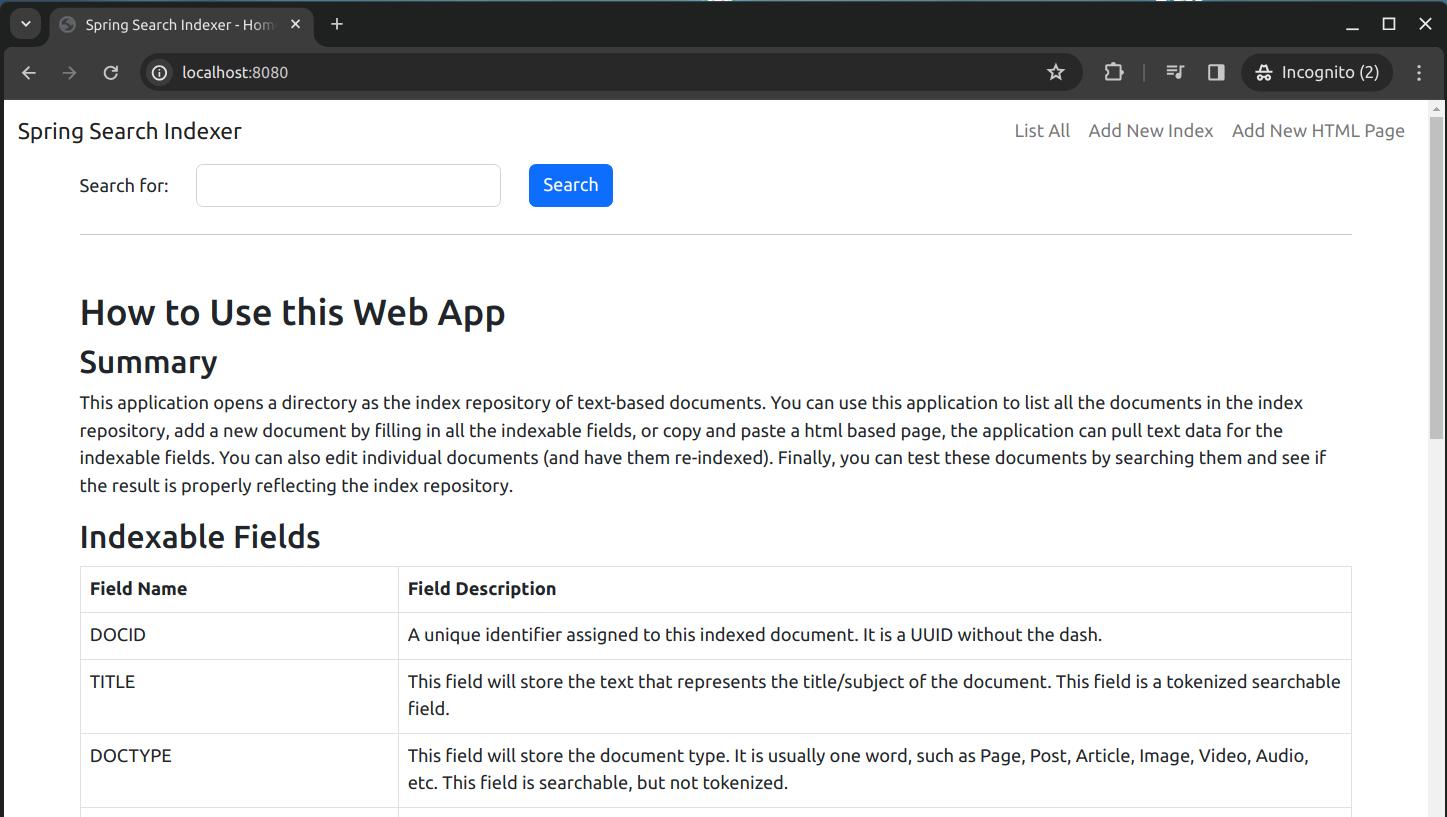
There are three more pages:
On the page "List All", for every row it displays, there are two links, one for editing the indexed document, and one to delete this index.
To create some document in the index repository, you can use the "Add New Index" page, just fill in all the fields and click the button "Save". Once the document is saved, it will appear in the "List All" page.
Screenshot of the "Add New Index" page:
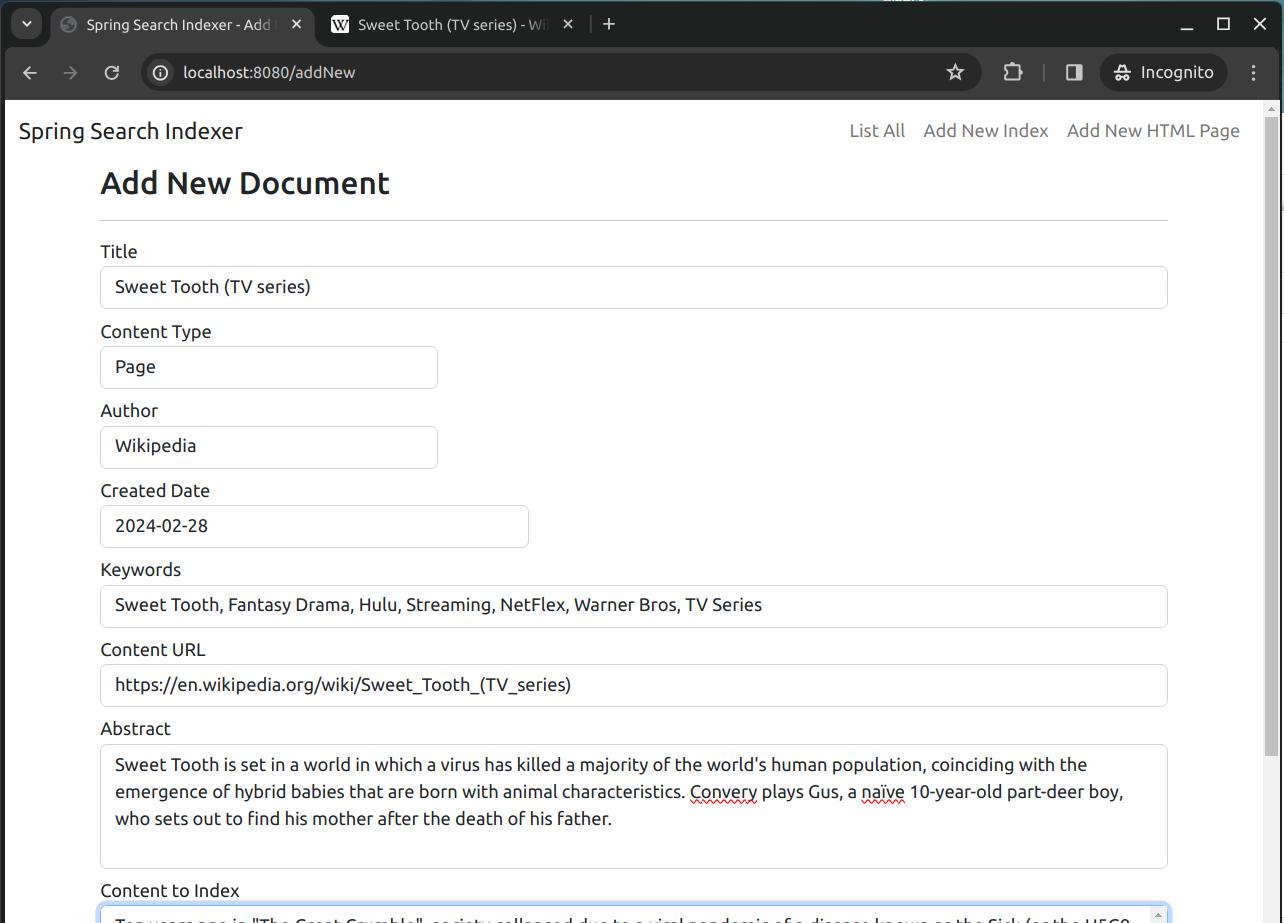
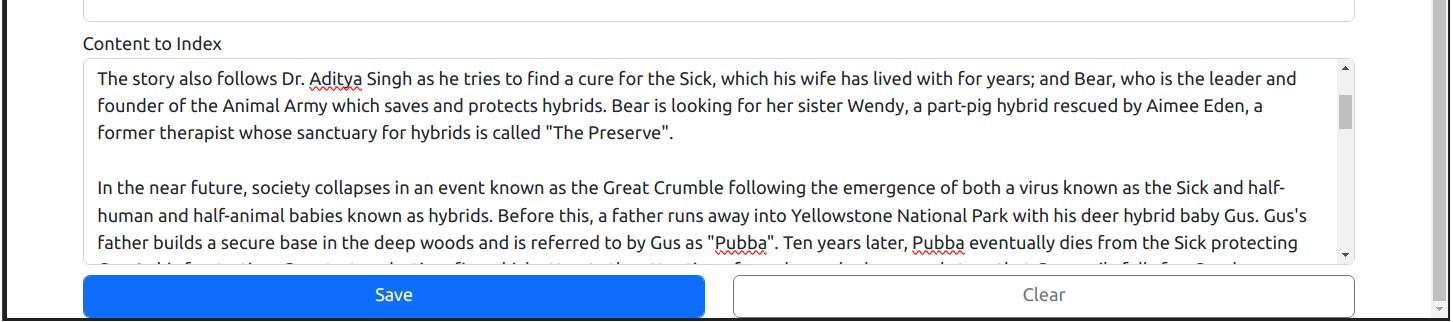
Screenshot of the "Add New Index" page where you can save the new index:
This is the "List All" page that displays all the indexed documents:
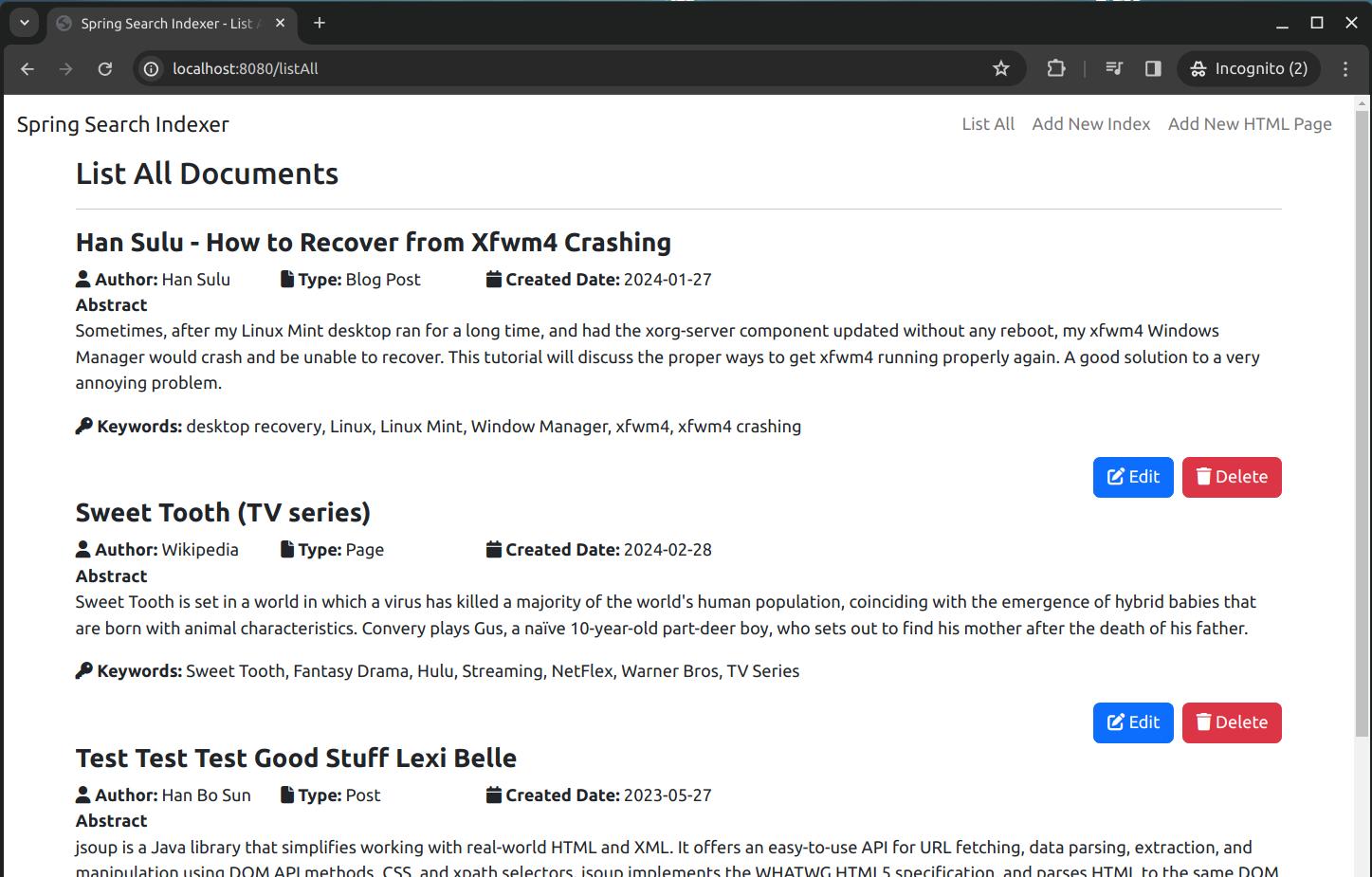
As you can see, every record in the list has two buttons: One for deleting the record from repository, and one for editing the record. The "Delete" button, when clicked, will delete the record without any warning. When you click on the "Edit" button for any of the records, it will show a page looks like this:
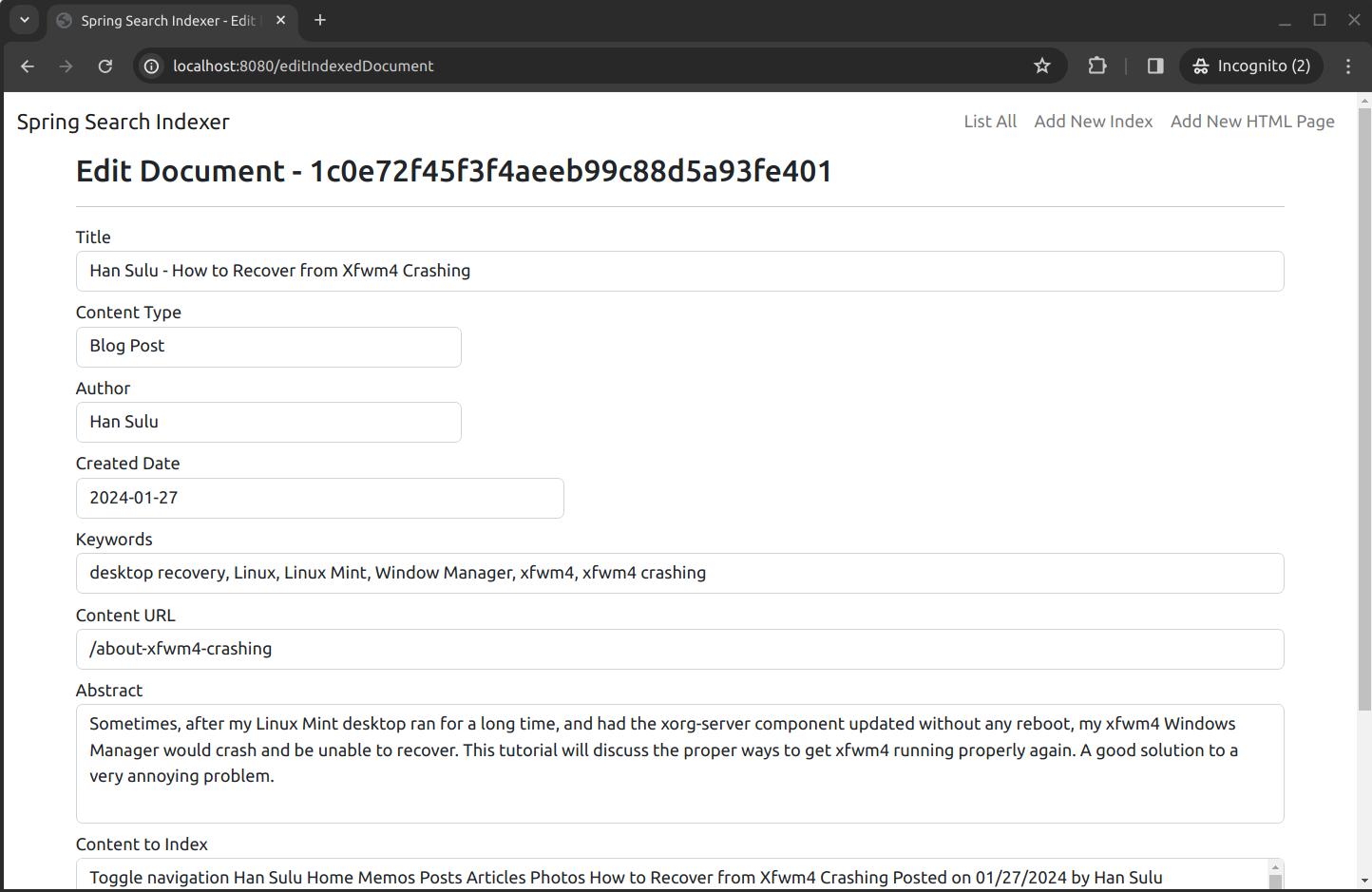
You can modify anything in the page. Then you can go to the bottom and click the "Save" to save the changes. The modified document will replace the un-modeified one in the index repository.
Let's take a look at the page that you can enter an HTML document and index it. It is the "Add New HTML Page". When you get to the page, it will look like this at first:
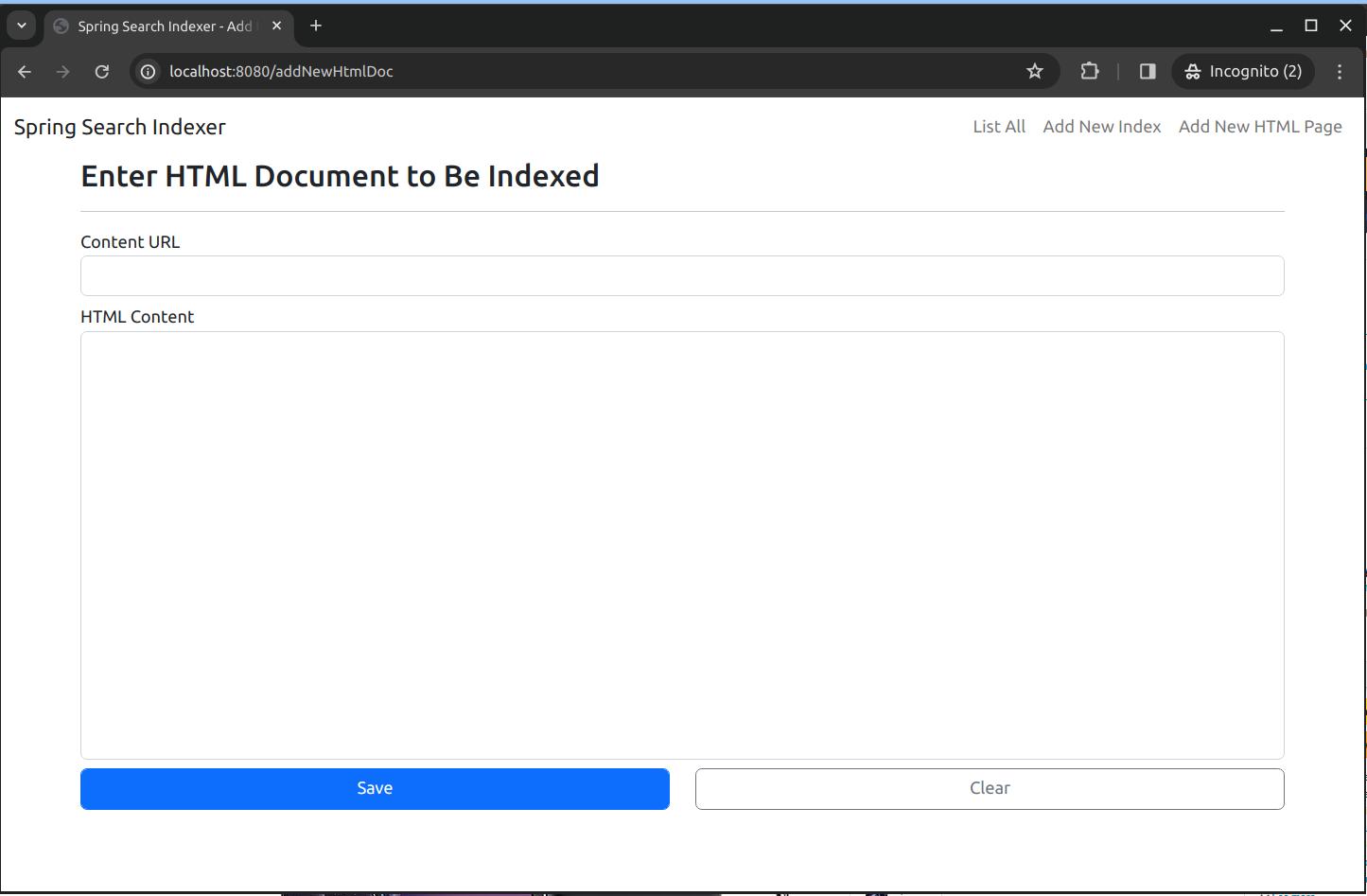
Again, I want to point out that only well formatted HTML document can be indexed properly uing this page. This sample application cannot process any HTML source code and expected to retrieve the required field data for document indexing. It can only expect certain places in the HTML source have the field data. And it retrieve these data from these locations within the HTML source. Please take a careul look at the section "Indexing HTML Pages" for more details.
This is the point where I conclude my tutorial. This has been a fun project for me. It is small and useful. And I took a long while to get it done. This tutorial offers an application that allows the user to manage a small Lucene index repository. It is capable of listing all the indexed documents, allowing users to retrieve the data of an indexed document, and updating the document then saving it. It also provides the functionality of deleting an existing document from the index repository. In addition, you can add a new document to the index repository, and you can index an HTML page source if it contains all the indexable field data in the right places.
Unlike my previous tutorial on Lucene, this tutorial explains how we can list all the documents, and how to retrieve and save changes on existing documents. It also provided the approach of a better full-text search, allowing users to enter more than one word for the full-text search. This approach is not perfect if you have common words like "the", "a", "this", "that", etc. in your search text, the application will match almost all the documents in the repository. I didn't use the ranking score in the search results to optimize the search results. It could be a solution to obtain more optimized results. Alternatively, I can remove these high-frequency search keywords and only match the words that matter. There are all kinds of ways I can optimize the full-text search functionality.
In this tutorial, I also introduced a way of parsing HTML pages and indexing the parsed data as searchable documents. What I have discussed in this tutorial is a simple HTML parser using JSoup. It can only parse the data from specific locations in the HTML source code. With a lot of hard work, you can expand this parser to parse information from any HTML page. That will be a different story. Anyway, I hope this tutorial will be useful to you. Good luck!
2/8/2024 - Initial Draft
Guest comment is not allowed for this post.

There is no comments to this post/article.