
Recently, I decided to learn how to load and display PDFs on an AngularJS based web application. There is no specific reason I want to do this, I want to learn how this can be done. Although, there is one time that an opportunity was there for such an integration to be done on a real-world project, and someone "stole" it from me. No matter what, a hard-working guy like me will never allow the chance of learning to escape me. And I will find time to learn it if such a chance interests me. After I successfully get the integration working, I find it really simple, yet it is truly powerful. This tutorial will show you how to set up the Spring Boot based web application, integrate PDF.js to a simple AngularJS based application, then load a PDF file and display it on the page.
This tutorial will start with an overview of the architecture, such as the structure of the back-end code and the front-end AngularJS application design. Then, the tutorial will discuss how this sample application can be built and used for a test run. At the very end, I will explain how this can be integrated with security, or what potential applications can be designed with such an integration.
Comparing to the past tutorials, this one is fairly simple. It has a back end server application that serves the PDF file to the front end application. The server application also delivers the page that runs the front end application. It is written with Spring Boot. I used the latest version (3.0.5 at the time I wrote the sample application). Besides serving the static web page, this application can serve the pdf file content via a REST API call. I will show you how this is implemented. This is the easy part. The hard part is about the integration of PDF.js into the AngularJS application.
There are a lot of good tutorials on how to add PDF.js to a JavaScript based web application. All of them use the same approach. Some of them are advanced, showing ways of zooming the content and making page flips. This tutorial will not show the content zooming but will show how page flips can be done. It will also explain how the PDF.js component can be initialized. This part is the hardest to understand, and most worthy to be explained.
I will start with the Maven POM file. It uses Java 17 and the latest Spring Boot. Next, it will be the RESTFul controller and the method that serves the PDF file content. Without further adieu, let's begin with the tutorial.
Let me start the discussion with the Maven POM file. The reason I want to do this is that I have moved the sample application from 2.7.x to the new version 3.0.5.
First, I have defined the following properties for the Maven execution process:
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
The first two lines set the source and target Java runtime version to Java 17. The third line sets the source file encoding to UTF-8. The Maven build will treat the files accordingly.
Next, I will define the Spring Boot parent dependency to version 3.0.5:
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.0.5</version>
</parent>
For the actual project dependency, I include the latest version of commons-io. This library makes it really easy to copy one data stream into another. It is something I use frequently:
<dependencies>
...
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.11.0</version>
</dependency>
</dependencies>
I also need to change the packaging plugin for the Spring Boot application to 3.0.5 as well:
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>3.0.5</version>
</plugin>
</plugins>
</build>
These are all the new changes I have made to the POM file of this new project compared to the past tutorials I have done.
We are almost at the most interesting part, so please bear with me for a little bit longer. In this section, I want to show how the PDF file is sent to the client side when it makes the request. It's pretty simple:
package org.hanbo.boot.rest.controllers;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.commons.io.IOUtils;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.RestController;
import jakarta.servlet.http.HttpServletResponse;
@RestController
public class PdfLoadController
{
@RequestMapping(value = "/loadPdf", method = RequestMethod.GET,
produces = MediaType.APPLICATION_PDF_VALUE)
public void loadPdf(HttpServletResponse response) throws IOException
{
File pdfFile = new File("<Project base folder full path>/test1.pdf");
if (pdfFile.exists())
{
long fileSize = pdfFile.length();
response.setContentLengthLong(fileSize);
response.setContentType("application/pdf");
FileInputStream fs = null;
try
{
fs = new FileInputStream(pdfFile);
IOUtils.copy(fs, response.getOutputStream());
response.flushBuffer();
}
finally
{
if (fs != null)
{
fs.close();
}
}
}
}
}
The above code snippet is not hard. First I create a File object. The parameter value specifies the full path of the file. Then the code checks if the file exists. If the file exists, it will load the entire file into the response object and set the response content length as well as the content type. When the method completes its operation, the response will be sent to the client. I used IOUtils.copy() to simplify the operation of loading the file input stream, and then dumping the data into the response output stream. See, one line does the trick, which is why I needed the commons-io library. It makes my life easy.
Now we are ready for the most interesting part of this tutorial, integrating the PDF.js component into an AngularJS based web application. Are you ready? Quick, to the next section.
Getting PDF.js integrated into my sample application is like making a pizza. This is the section where you will see how the delicious pizza is made. As we know, making pizza is a known process. How the pizza is made determines how good the pizza will be. I had to do some research before I started working on the sample project. The link I used is the following:
https://mozilla.github.io/pdf.js/examples/
Mozilla org provided this tutorial. It is very comprehensive and easy to understand. I include it here for your reference. You should read it, it is very helpful. I took the sample code in this tutorial, and make the changes so that it can be easily added into my sample application. It can easily (I hope) be moved into any similar AngulrJS application.
Let me show you the design for the service class that loads and displays the pdf content. Here it is:
export class PdfLoadService {
constructor () {
console.log("initialize PDF JS");
this._pdfjslib = window['pdfjs-dist/build/pdf'];
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://mozilla.github.io/pdf.js/build/pdf.worker.js';
}
loadPdf(url) {
return this._pdfjslib.getDocument(url).promise;
}
getPdfPage(pdf, pageNum) {
if (pdf) {
return pdf.getPage(pageNum);
} else {
return null;
}
}
renderPage(pdfPage, canvas) {
if (pdfPage && canvas) {
pdfPage.then(function (page) {
let scale = 1.0;
let viewport = page.getViewport({ scale: scale });
let context = canvas.getContext('2d');
canvas.height = viewport.height;
canvas.width = viewport.width;
let renderContext = {
canvasContext: context,
viewport: viewport
};
page.render(renderContext).promise.then(function () {
console.log("Rendering complete...");
});
});
}
}
}
This is not like the JavaScript classes I have written in the past. There are a few places that are hard to understand. The first one is in the constructor:
constructor () {
console.log("initialize PDF JS");
this._pdfjslib = window['pdfjs-dist/build/pdf'];
pdfjsLib.GlobalWorkerOptions.workerSrc = 'https://mozilla.github.io/pdf.js/build/pdf.worker.js';
}
The line that is bold and underlined is the hardest to understand, in my opinion of course. When I first saw this line, it took a while for me to know what it does. To understand it, imagine the word window is an object (it is in fact an object). For JavaScript objects, you can access its properties in two ways. The first is using the dot operator to access the properties. The other one is to treat the object as a hash map and use a key to access the property value associated with this key. The highlighted line uses the second way to get the value. The key is 'pdfjs-dist/build/pdf'. Here is a screenshot of the property in the JavaScript debugger:
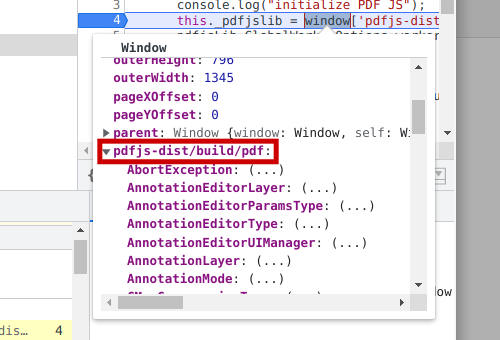
The highlighted line assigns the value of the property 'pdfjs-dist/build/pdf' to the instance property this._pdfjslib of the class PdfLoadService. It can be used by all the methods of this class. The next line assigns the source code of the worker. This one I also copied from the tutorial. I guess since the PDF.js library uses "promises" extensively, the worker source is probably the code that creates a separate thread, does the loading/rendering, then notify the main thread that work has been completed. This is my guess, the official tutorial didn't say what it does. I guess the team that developed this library doesn't care if anyone really wants to know what this line does. As long as a person can copy this line correctly from their tutorial and make the library work, it is all good.
The next method takes an URL of the pdf, loads it using the _pdfjslib object and returns a "promise" to the caller. When the other objects uses this PdfLoadService object to load and render a PDF file, this will be the first method to call.
loadPdf(url) {
return this._pdfjslib.getDocument(url).promise;
}
The next method can extract a specific page from the PDF content, it takes two parameters, one is the pdf data object loaded by the previous method. The other parameter is the numeric value representing the page number. Note, the PDF content page starts at 1, not 0. And the last page index would be the same value as the total number of pages.
getPdfPage(pdf, pageNum) {
if (pdf) {
return pdf.getPage(pageNum);
} else {
return null;
}
}
This method also returns a "promise". The "promise" contains the page info as well as the content data. Once they are available, the page can be rendered by the last method.
The last method is more complex than the other two. It takes in two parameters. The first one is the pdf page info and content data, the second is a reference to a canvas object on the page. The whole method looks like this:
renderPage(pdfPage, canvas) {
if (pdfPage && canvas) {
pdfPage.then(function (page) {
let scale = 1.0;
let viewport = page.getViewport({ scale: scale });
let context = canvas.getContext('2d');
canvas.height = viewport.height;
canvas.width = viewport.width;
let renderContext = {
canvasContext: context,
viewport: viewport
};
page.render(renderContext).promise.then(function () {
console.log("Rendering complete...");
});
});
}
}
This service class is only half of the whole story. It provides the functionality of loading and rendering the pdf content. But it doesn't do it by itself. Something else has to use this service class to exercise these functionalities. And this something is the AppController. The sample application is a one-page application. It displays a Bootstrap panel, and in it the pdf content. Here is the full source code of the AppController:
export class AppController {
constructor($rootScope, $scope, $timeout, pdfLoadService) {
this._rootScope = $rootScope;
this._scope = $scope;
this._pdfLoadService = pdfLoadService;
this._errorMsg = "";
this._pdfData = null;
this._pagesCount = 0;
this._currPageIdx = 0;
this._scope.$watch("vm.pdfData", this.pdfDataReady);
this.initializePdfFile();
}
get pdfData() {
return this._pdfData;
}
set pdfData(val) {
this._pdfData = val;
}
get currPageIndex () {
return this._currPageIdx;
}
set currPageIndex (val) {
this._currPageIdx = val;
}
get pagesCount () {
return this._pagesCount;
}
set pagesCount (val) {
this._pagesCount = val;
}
pdfDataReady = function(newVal, oldVal, scope) {
if (oldVal == null && newVal != null) {
// a new pdf docuement is available;
console.log("A new pdf docuement is available;");
if (scope && scope.vm) {
let origin = scope.vm;
origin._currPageIdx = 1;
origin.displayPdfPage(origin._currPageIdx);
}
} else if (oldVal != null && newVal == null) {
// unloading an existing pdf file.
console.log("Unloading an existing pdf file.");
if (scope && scope.vm) {
scope.vm._currPageIdx = 0;
scope.vm._pagesCount = 0;
}
}
}
initializePdfFile() {
let self = this;
self._pdfLoadService.loadPdf("/loadPdf")
.then (function (pdf) {
if (pdf && pdf._pdfInfo) {
self._pdfData = pdf;
self._pagesCount = pdf._pdfInfo.numPages;
self._scope.$apply();
}
}, function (error) {
if (error) {
console.log(error);
}
self.errorMsg = "Unable to load PDF file for display.";
self._scope.$apply();
});
}
prevousPage = function() {
if (this._pagesCount > 0) {
if (this._currPageIdx > 1) {
this._currPageIdx--;
} else {
this._currPageIdx = 1;
}
this.displayPdfPage(this._currPageIdx);
}
}
nextPage = function () {
if (this._pagesCount > 0) {
if (this._currPageIdx < this._pagesCount) {
this._currPageIdx++;
} else {
this._currPageIdx = this._pagesCount;
}
this.displayPdfPage(this._currPageIdx);
}
}
displayPdfPage = function(pageIdx) {
let pdfPage = this._pdfLoadService.getPdfPage(this.pdfData, pageIdx);
if (pdfPage) {
let canvas = angular.element("#pdfViewArea");
if (canvas && canvas.length > 0) {
let canvasElem = canvas[0];
this._pdfLoadService.renderPage(pdfPage, canvasElem);
}
}
}
}
This class is a little bit more complex than the service class I have shown above. Before I dig into the details of this class, let me explain how the page works. After the page is loaded, it will attempt to load the pdf by invoking the backend API. Once the PDF data is successfully loaded, the first page will be displayed in the panel. At the bottom of the page, there are two buttons with arrow symbols, that can be used to flip the pages of the pdf content. Between the buttons, there is the display of page index and total page count. Now, it is time to dig into the code above. First, we start with the constructor:
constructor($rootScope, $scope, $timeout, pdfLoadService) {
this._rootScope = $rootScope;
this._scope = $scope;
this._pdfLoadService = pdfLoadService;
this._errorMsg = "";
this._pdfData = null;
this._pagesCount = 0;
this._currPageIdx = 0;
this._scope.$watch("vm.pdfData", this.pdfDataReady);
this.initializePdfFile();
}
The top part is the initialization of instance properties. Once these properties are assigned with the initial values, they can be referenced anywhere in the same object. The last two lines are setting up a watcher, and the loading of the pdf content.
Why do I need a watcher? This is a great question. The way I utilize my service class is different from the Mozilla org's tutorial. Once I load the PDF content, I want to store the pdf data object so that I can load the pages out and do the rendering at will. Let's take a look at the method initializePdfFile(). This method does the loading of the pdf content:
initializePdfFile() {
let self = this;
self._pdfLoadService.loadPdf("/loadPdf")
.then (function (pdf) {
if (pdf && pdf._pdfInfo) {
self._pdfData = pdf;
self._pagesCount = pdf._pdfInfo.numPages;
self._scope.$apply();
}
}, function (error) {
if (error) {
console.log(error);
}
self.errorMsg = "Unable to load PDF file for display.";
self._scope.$apply();
});
}
As you can see, I used my _pdfLoadService to load the pdf content data. Once the "promise" returns, I pass the PDF data to the instance property self._pdfData. This way, it can be used anywhere in the same object. You might also notice that I used "self._scope.$apply();". This call usually is not necessary because when the value change of an AngularJS model in the current scope, this is called automatically by the framework. However, the loading is done with PDF.js code, and the "promise" will take the execution out of the current AngularJS scope, so the $apply() will not be called automatically.
Once the PDF data is loaded successfully, I need to display it. As you see in the method initializePdfFile(), there is no code that renders the first page of the PDF content. This is my intention. What if the web page wants to clear the current PDF data and load a new one? When this happens, I can use a similar way to load new PDF content, then notify the controller that the data are ready. This is the reason I need a watcher. This is the method which the watcher subscribes to:
pdfDataReady = function(newVal, oldVal, scope) {
if (oldVal == null && newVal != null) {
// a new pdf docuement is available;
console.log("A new pdf docuement is available;");
if (scope && scope.vm) {
let origin = scope.vm;
origin._currPageIdx = 1;
origin.displayPdfPage(origin._currPageIdx);
}
} else if (oldVal != null && newVal == null) {
// unloading an existing pdf file.
console.log("Unloading an existing pdf file.");
if (scope && scope.vm) {prevousPage = function() {
if (this._pagesCount > 0) {
if (this._currPageIdx > 1) {
this._currPageIdx--;
} else {
this._currPageIdx = 1;
}
this.displayPdfPage(this._currPageIdx);
}
}
scope.vm._currPageIdx = 0;
scope.vm._pagesCount = 0;
}
}
}
This method is a bit hard to understand. It takes three parameters: new value, old value, and the scope where the value change takes place. I needed all three. I use the first two to compare and see if the value of this._pdfData changed from no value to valid PDF content or the other way around, then perform an operation accordingly. If a new value is valid PDF content, I need to set the page index to 1 (it starts at 1, not 0), and render this first page. If the new value becomes null, that means there used to be some PDF content, not it is gone. In this case, I need to reset the page index to 0, the total page value to 0. Here is how I subscribe the watcher to this method:
this._scope.$watch("vm.pdfData", this.pdfDataReady);
Here is the method in this AppController that renders the PDF content to the page:
displayPdfPage = function(pageIdx) {
let pdfPage = this._pdfLoadService.getPdfPage(this.pdfData, pageIdx);
if (pdfPage) {
let canvas = angular.element("#pdfViewArea");
if (canvas && canvas.length > 0) {
let canvasElem = canvas[0];
this._pdfLoadService.renderPage(pdfPage, canvasElem);
}
}
}
This method uses the service object to get the page specified by the parameter pageIdx. The call will return a PDF page data object (not a "promise"). Once the code is sure that the PDF page data object is valid, it will get a reference of the HTML canvas element, and use the service object as well as the PDF page data object to render the page for display.
As you can see, I have broken the loading of the PDF, the extracting of the PDF page, and the rendering of the page operations into three loose coupled operations. I can use them anywhere in the same controller. I have shown this with the watcher configuration. As soon as the PDF data is available, the watcher gets notified and does the rendering. The whole design is pretty neat. And with this, I can easily implement the functionality of flipping the pages. Here is the method that does the page flip for the previous pages:
prevousPage = function() {
if (this._pagesCount > 0) {
if (this._currPageIdx > 1) {
this._currPageIdx--;
} else {
this._currPageIdx = 1;
}
this.displayPdfPage(this._currPageIdx);
}
}
As you see, the operation is very simple, the current page index is tracked by the object of AppController. After loading the PDF content data, the controller also knows the total number of pages. The navigation is really a decrement of the current page index and some check whether the new value is valid or not. The same goes for the page flip to get to the next page. The difference is incrementing the page index instead of decrementing the page index:
nextPage = function () {
if (this._pagesCount > 0) {
if (this._currPageIdx < this._pagesCount) {
this._currPageIdx++;
} else {
this._currPageIdx = this._pagesCount;
}
this.displayPdfPage(this._currPageIdx);
}
}
That is it! All the most important parts of this sample application. The rest of the source codes, you can read them yourself. It is available in the navigation section on the left side of this tutorial. The HTML page markup is similar to what I have done in many of my previous tutorials. They are not new. I don't want to spend time and repeat myself. I have done it a lot in the past two years. Let's go to the next section, in which I will explain how you can build and run the sample application.
After you download the source code, please rename all the *.sj files to *.js files. I renamed them so that I can easily email my tutorial content to codeproject.com. If you want the sample application to work, you need to rename these files.
I have prepared a sample PDF file for the demonstration in the sample application. However, the file path to this PDF file is a dummy value, please put an accessible full path to this PDF file, or you won't be able to load the PDF file. And the demonstration will fail. This can be done in the Java file "PdfLoadController.java".
To build the project, please open a terminal or cmd.exe window, then cd into the folder where you see the pom.xml file. Then run the following command:
mvn clean install
After the project is built successfully, run the following command in the same folder to start the application:
java -jar target/hanbo-angularjs-pdf-display-sample-1.0.1.jar
The sample application should start up successfully, if the preparation work is done correctly before building the project. You can open a browser, and navigate to the following url:
http://localhost:8080/
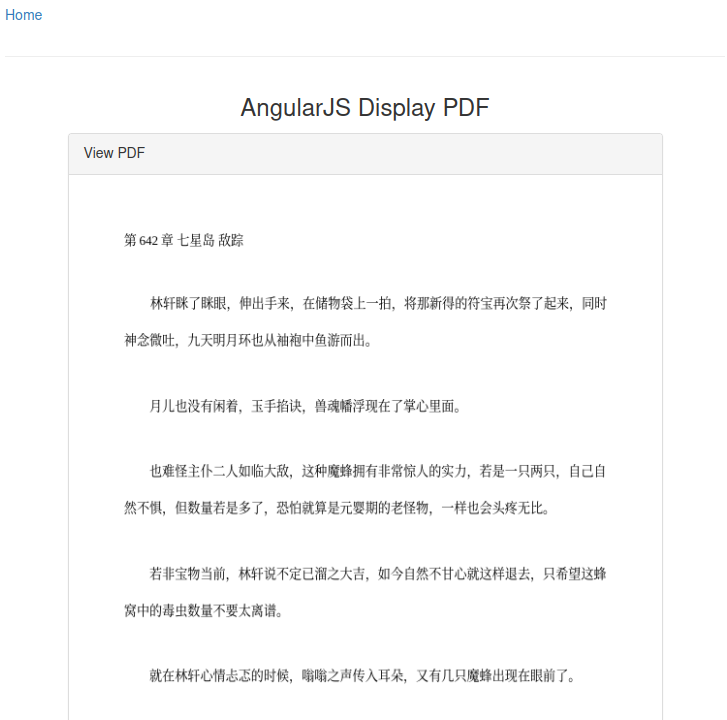
If everything is correct, you should see the following page:
At the bottom, you should see two buttons, one on each side. If you click them, you should be able to flip to the previous or the next page. If there is no more page for the button, the current page will be rendered again.
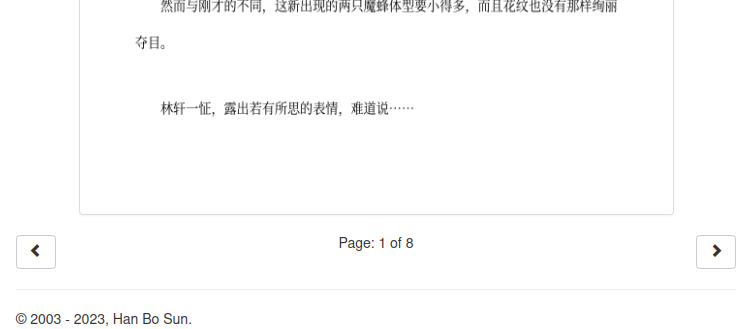
If you right-click on the canvas, there is an option on the popup context menu allowing you to download it. And it saves as a PNG image file (at least that is how it behaves on my Linux desktop). This means that the rendered canvas object is actually an image.
That is all. In the next section, I will be discussing how to apply the integration into more complex web applications. And I will also reveal the potential applications that I can utilize with the PDF.js library.
That was a fun tutorial to work on. It is fun because I learned a few things during this work. I realized that PDF.js is a very useful tool. It can bring me some new opportunities. Before I get to that, I like to discuss some advanced use of PDF.js. Imagine the scenario where the PDF content served by the back end is a protected resource, the HTTP request to fetch the PDF content must contain authorization information for it to be processed correctly. Or the request will meet with a 401 error. As you have seen, the PDF.js library handles the request to the backend server itself. It might not be possible to inject security-related data into the request. Also, PDF.js might use HTTP GET to fetch the PDF content from the backend, but sometimes you might want to serve the content by other HTTP methods. Then PDF.js will not be able to get the PDF content. All these problems can be avoided if you can serve the PDF content as a binary data stream and encode it as a BASE64 string, sending that to the front end, then PDF.js can consume it without much trouble. This also prevents evil-minded people from getting the PDF content as a file easily. Even if the person gets the data stream, they have to decode and save it as a PDF file, which is two extra steps. Implementing such a mechanism might discourage some from getting the PDF content easily. Then again, this mechanism is not 100% bulletproof. It will not discourage all evil-minded people from taking advantage of your content data.
So what do I gain from learning this? PDF.js can be easily integrated into a web application to display things like receipts, or blueprints of floor plans, nice-looking reports, and presentations. None of these is important to me. There is a specific use case that I am most interested in. There are a lot of large Chinese websites that publish long serialized novels. These sites use a lot of mechanisms to discourage users from copying and pasting novel content to another site. Even so, I found it pretty easy to use Deveroper's Tools to extract the content from these sites. With this tutorial, I can design such a site with a new approach, the authors can submit content as a PDF file. When it is served, it is displayed as an image file, and I can disable right click function to the canvas, page. This would make it hard for someone to commit copyright violations. They have to open the Deveroper's Tool, find the image, download it, then use some kind of scanning application to extract the text. Maybe one day, I will start working on an MVP project on this idea. Anyways, I hope this tutorial is fun and helpful for you. Thank you for reading, and good luck.
Guest comment is not allowed for this post.

There is no comments to this post/article.